Our newest mannequin, Claude Opus 4.7, is now usually obtainable.
Opus 4.7 is a notable enchancment on Opus 4.6 in superior software program engineering, with specific features on probably the most tough duties. Users report with the ability to hand off their hardest coding work—the type that beforehand wanted shut supervision—to Opus 4.7 with confidence. Opus 4.7 handles advanced, long-running duties with rigor and consistency, pays exact consideration to directions, and devises methods to confirm its personal outputs earlier than reporting again.
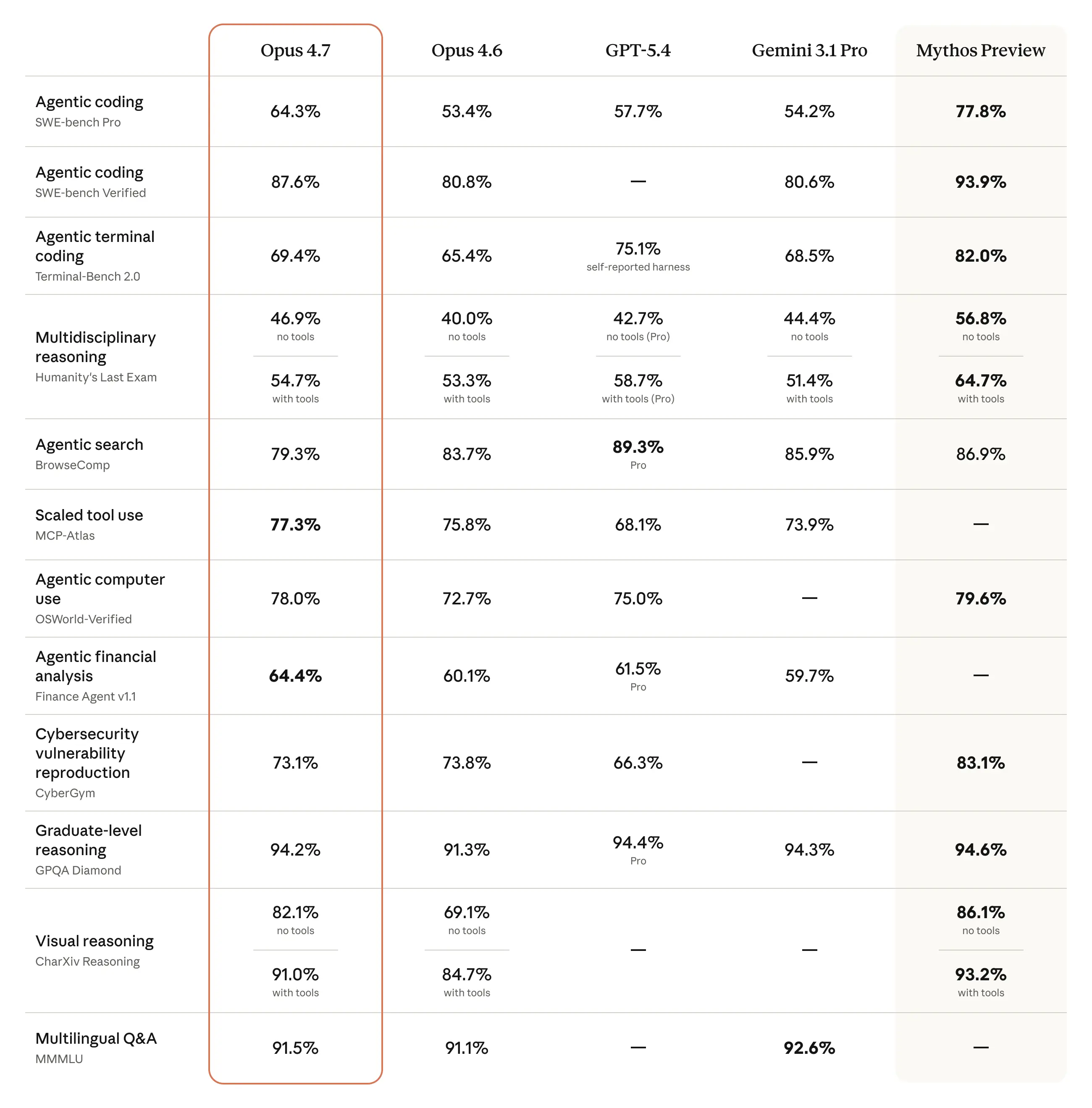
The mannequin additionally has considerably higher imaginative and prescient: it may possibly see photographs in better decision. It’s extra tasteful and artistic when finishing skilled duties, producing higher-quality interfaces, slides, and docs. And—though it’s much less broadly succesful than our strongest mannequin, Claude Mythos Preview—it reveals higher outcomes than Opus 4.6 throughout a spread of benchmarks:
Last week we introduced Project Glasswing, highlighting the dangers—and advantages—of AI fashions for cybersecurity. We acknowledged that we’d hold Claude Mythos Preview’s launch restricted and take a look at new cyber safeguards on much less succesful fashions first. Opus 4.7 is the primary such mannequin: its cyber capabilities should not as superior as these of Mythos Preview (certainly, throughout its coaching we experimented with efforts to differentially scale back these capabilities). We are releasing Opus 4.7 with safeguards that robotically detect and block requests that point out prohibited or high-risk cybersecurity makes use of. What we be taught from the real-world deployment of those safeguards will assist us work in direction of our eventual aim of a broad launch of Mythos-class fashions.
Security professionals who want to use Opus 4.7 for respectable cybersecurity functions (resembling vulnerability analysis, penetration testing, and red-teaming) are invited to affix our new Cyber Verification Program.
Opus 4.7 is accessible right this moment throughout all Claude merchandise and our API, Amazon Bedrock, Google Cloud’s Vertex AI, and Microsoft Foundry. Pricing stays the identical as Opus 4.6: $5 per million enter tokens and $25 per million output tokens. Developers can use claude-opus-4-7 by way of the Claude API.
Testing Claude Opus 4.7
Claude Opus 4.7 has garnered robust suggestions from our early-access testers:
In early testing, we’re seeing the potential for a big leap for our builders with Claude Opus 4.7. It catches its personal logical faults through the planning section and accelerates execution, far past earlier Claude fashions. As a monetary know-how platform serving thousands and thousands of customers and companies at vital scale, this mixture of pace and precision might be game-changing: accelerating improvement velocity for sooner supply of the trusted monetary options our clients depend on each day.
Anthropic has already set the usual for coding fashions, and Claude Opus 4.7 pushes that additional in a significant manner because the state-of-the-art mannequin available on the market. In our inside evals, it stands out not only for uncooked functionality, however for the way nicely it handles real-world async workflows—automations, CI/CD, and long-running duties. It additionally thinks extra deeply about issues and brings a extra opinionated perspective, slightly than merely agreeing with the consumer.
Claude Opus 4.7 is the strongest mannequin Hex has evaluated. It appropriately reviews when knowledge is lacking as an alternative of offering plausible-but-incorrect fallbacks, and it resists dissonant-data traps that even Opus 4.6 falls for. It’s a extra clever, extra environment friendly Opus 4.6: low-effort Opus 4.7 is roughly equal to medium-effort Opus 4.6.
On our 93-task coding benchmark, Claude Opus 4.7 lifted decision by 13% over Opus 4.6, together with 4 duties neither Opus 4.6 nor Sonnet 4.6 may clear up. Combined with sooner median latency and strict instruction following, it’s significantly significant for advanced, long-running coding workflows. It cuts the friction from these multi-step duties so builders can keep within the stream and give attention to constructing.
Based on our inside research-agent benchmark, Claude Opus 4.7 has the strongest effectivity baseline we’ve seen for multi-step work. It tied for the highest general rating throughout our six modules at 0.715 and delivered probably the most constant long-context efficiency of any mannequin we examined. On General Finance—our largest module—it improved meaningfully on Opus 4.6, scoring 0.813 versus 0.767, whereas additionally exhibiting the most effective disclosure and knowledge self-discipline within the group. And on deductive logic, an space the place Opus 4.6 struggled, Opus 4.7 is stable.
Claude Opus 4.7 extends the restrict of what fashions can do to analyze and get duties achieved. Anthropic has clearly optimized for sustained reasoning over lengthy runs, and it reveals with market-leading efficiency. As engineers shift from working 1:1 with brokers to managing them in parallel, that is precisely the type of frontier functionality that unlocks new workflows.
We’re seeing main enhancements in Claude Opus 4.7’s multimodal understanding, from studying chemical buildings to decoding advanced technical diagrams. The larger decision help helps Solve Intelligence construct best-in-class instruments for all times sciences patent workflows, from drafting and prosecution to infringement detection and invalidity charting.
For Replit, Claude Opus 4.7 was a simple improve determination. For the work our customers do each day, we noticed it attaining the identical high quality at decrease price—extra environment friendly and exact at duties like analyzing logs and traces, discovering bugs, and proposing fixes. Personally, I really like the way it pushes again throughout technical discussions to assist me make higher choices. It actually looks like a greater coworker.
Claude Opus 4.7 demonstrates robust substantive accuracy on BigLaw Bench for Harvey, scoring 90.9% at excessive effort with higher reasoning calibration on assessment tables and noticeably smarter dealing with of ambiguous doc modifying duties. It appropriately distinguishes project provisions from change-of-control provisions, a job that has traditionally challenged frontier fashions. Substance was constantly rated as a energy throughout our evaluations: right, thorough, and well-cited.
Claude Opus 4.7 is a really spectacular coding mannequin, significantly for its autonomy and extra artistic reasoning. On CursorBench, Opus 4.7 is a significant soar in capabilities, clearing 70% versus Opus 4.6 at 58%.
For advanced multi-step workflows, Claude Opus 4.7 is a transparent step up: plus 14% over Opus 4.6 at fewer tokens and a 3rd of the instrument errors. It’s the primary mannequin to cross our implicit-need checks, and it retains executing by instrument failures that used to cease Opus chilly. This is the reliability soar that makes Notion Agent really feel like a real teammate.
In our evals, we noticed a double-digit soar in accuracy of instrument calls and planning in our core orchestrator brokers. As customers leverage Hebbia to plan and execute on use circumstances like retrieval, slide creation, or doc era, Claude Opus 4.7 reveals the potential to enhance agent decision-making in these workflows.
On Rakuten-SWE-Bench, Claude Opus 4.7 resolves 3x extra manufacturing duties than Opus 4.6, with double-digit features in Code Quality and Test Quality. This is a significant elevate and a transparent improve for the engineering work our groups are delivery each day.
For CodeRabbit’s code assessment workloads, Claude Opus 4.7 is the sharpest mannequin we’ve examined. Recall improved by over 10%, surfacing a number of the most difficult-to-detect bugs in our most advanced PRs, whereas precision remained steady regardless of the elevated protection. It’s a bit sooner than GPT-5.4 xhigh on our harness, and we’re lining it up for our heaviest assessment work at launch.
For Genspark’s Super Agent, Claude Opus 4.7 nails the three manufacturing differentiators that matter most: loop resistance, consistency, and swish error restoration. Loop resistance is probably the most important. A mannequin that loops indefinitely on 1 in 18 queries wastes compute and blocks customers. Lower variance means fewer surprises in prod. And Opus 4.7 achieves the very best quality-per-tool-call ratio we’ve measured.
Claude Opus 4.7 is a significant step up for Warp. Opus 4.6 is likely one of the greatest fashions on the market for builders, and this mannequin is measurably extra thorough on high of that. It handed Terminal Bench duties that prior Claude fashions had failed, and labored by a tough concurrency bug Opus 4.6 could not crack. For us, that’s the sign.
Claude Opus 4.7 is the most effective mannequin on the earth for constructing dashboards and data-rich interfaces. The design style is genuinely shocking—it makes decisions I’d really ship. It’s my default every day driver now.
Claude Opus 4.7 is probably the most succesful mannequin we have examined at Quantium. Evaluated in opposition to main AI fashions by our proprietary benchmarking answer, the most important features confirmed up the place they matter most: reasoning depth, structured problem-framing, and complicated technical work. Fewer corrections, sooner iterations, and stronger outputs to unravel the toughest issues our purchasers convey us.
Claude Opus 4.7 looks like an actual step up in intelligence. Code high quality is noticeably improved, it’s slicing out the meaningless wrapper capabilities and fallback scaffolding that used to pile up, and fixes its personal code because it goes. It’s the cleanest soar we’ve seen because the transfer from Sonnet 3.7 to the Claude 4 collection.
For the computer-use work that sits on the coronary heart of XBOW’s autonomous penetration testing, the brand new Claude Opus 4.7 is a step change: 98.5% on our visual-acuity benchmark versus 54.5% for Opus 4.6. Our single greatest Opus ache level successfully disappeared, and that unlocks its use for an entire class of labor the place we couldn’t use it earlier than.
Claude Opus 4.7 is a stable improve with no regressions for Vercel. It’s phenomenal on one-shot coding duties, extra right and full than Opus 4.6, and noticeably extra trustworthy about its personal limits. It even does proofs on methods code earlier than beginning work, which is new habits we haven’t seen from earlier Claude fashions.
Claude Opus 4.7 may be very robust and outperforms Opus 4.6 with a ten% to fifteen% elevate in job success for Factory Droids, with fewer instrument errors and extra dependable follow-through on validation steps. It carries work right through as an alternative of stopping midway, which is precisely what enterprise engineering groups want.
Claude Opus 4.7 autonomously constructed a whole Rust text-to-speech engine from scratch—neural mannequin, SIMD kernels, browser demo—then fed its personal output by a speech recognizer to confirm it matched the Python reference. Months of senior engineering, delivered autonomously. The step up from Opus 4.6 is evident, and the codebase is public.
Claude Opus 4.7 handed three TBench duties that prior Claude fashions couldn’t, and it’s touchdown fixes our earlier greatest mannequin missed, together with a race situation. It demonstrates robust precision in figuring out actual points, and surfaces essential findings that different fashions both gave up on or didn’t resolve. In Qodo’s real-world code assessment benchmark, we noticed top-tier precision.
On Databricks’ OfficeQA Pro, Claude Opus 4.7 reveals meaningfully stronger doc reasoning, with 21% fewer errors than Opus 4.6 when working with supply data. Across our agentic reasoning over knowledge benchmarks, it’s the best-performing Claude mannequin for enterprise doc evaluation.
For Ramp, Claude Opus 4.7 stands out in agent-team workflows. We’re seeing stronger position constancy, instruction-following, coordination, and complicated reasoning, particularly on engineering duties that span instruments, codebases, and debugging context. Compared with Opus 4.6, it wants a lot much less step-by-step steering, serving to us scale the inner agent workflows our engineering groups run.
Claude Opus 4.7 is measurably higher than Opus 4.6 for Bolt’s longer-running app-building work, as much as 10% higher in the most effective circumstances, with out the regressions we’ve come to count on from very agentic fashions. It pushes the ceiling on what our customers can ship in a single session.
Below are some highlights and notes from our early testing of Opus 4.7:
- Instruction following. Opus 4.7 is considerably higher at following directions. Interestingly, because of this prompts written for earlier fashions can typically now produce surprising outcomes: the place earlier fashions interpreted directions loosely or skipped components solely, Opus 4.7 takes the directions actually. Users ought to re-tune their prompts and harnesses accordingly.
- Improved multimodal help. Opus 4.7 has higher imaginative and prescient for high-resolution photographs: it may possibly settle for photographs as much as 2,576 pixels on the lengthy edge (~3.75 megapixels), greater than thrice as many as prior Claude fashions. This opens up a wealth of multimodal makes use of that rely upon wonderful visible element: computer-use brokers studying dense screenshots, knowledge extractions from advanced diagrams, and work that wants pixel-perfect references.1
- Real-world work. As nicely as its state-of-the-art rating on the Finance Agent analysis (see desk above), our inside testing confirmed Opus 4.7 to be a simpler finance analyst than Opus 4.6, producing rigorous analyses and fashions, extra skilled displays, and tighter integration throughout duties. Opus 4.7 can be state-of-the-art on GDPval-AA, a third-party analysis of economically helpful data work throughout finance, authorized, and different domains.
- Memory. Opus 4.7 is best at utilizing file system-based reminiscence. It remembers essential notes throughout lengthy, multi-session work, and makes use of them to maneuver on to new duties that, in consequence, want much less up-front context.
The charts under show extra analysis outcomes from our pre-release testing, throughout a spread of various domains:
Safety and alignment
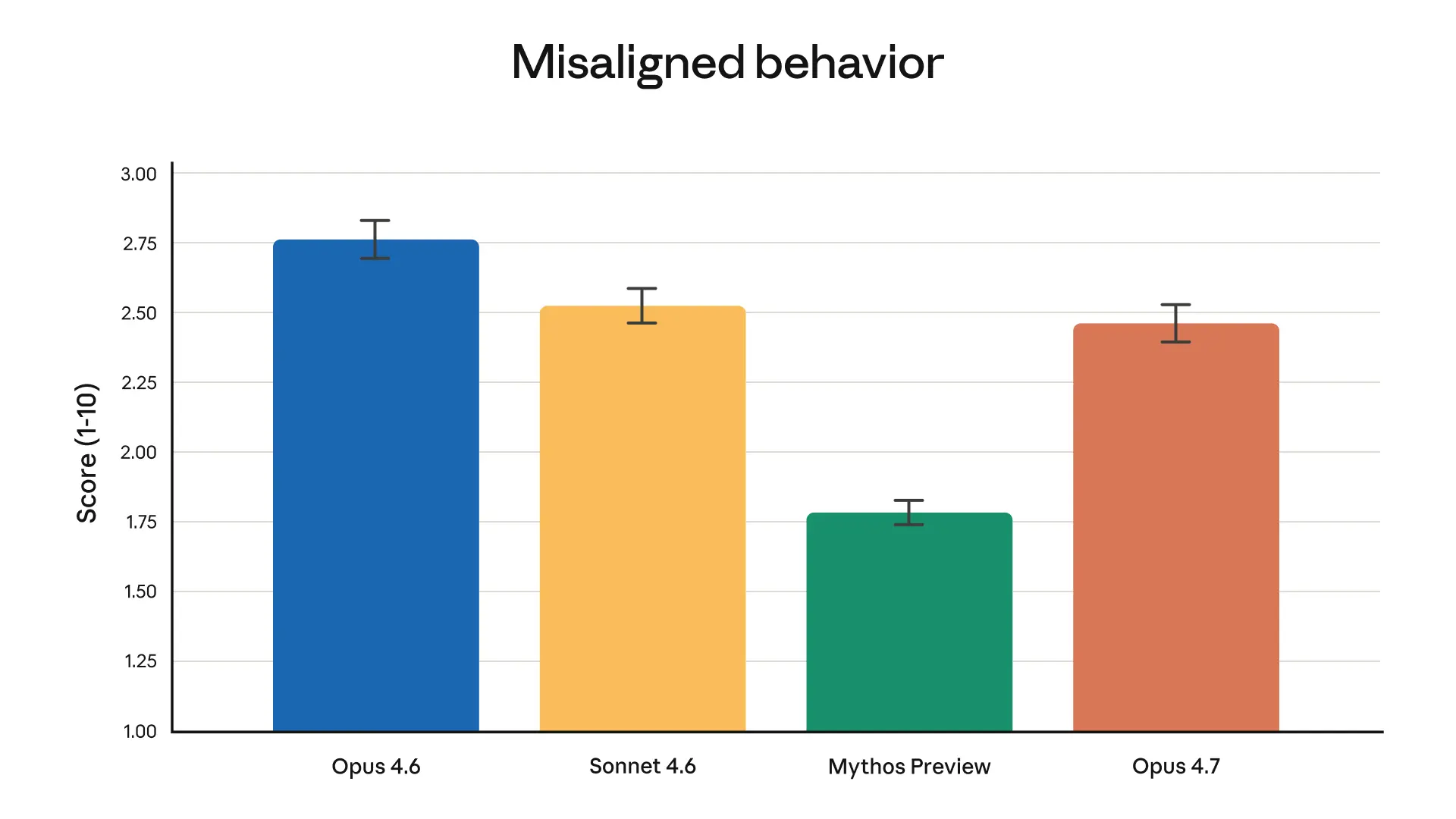
Overall, Opus 4.7 reveals an identical security profile to Opus 4.6: our evaluations present low charges of regarding habits resembling deception, sycophancy, and cooperation with misuse. On some measures, resembling honesty and resistance to malicious “prompt injection” assaults, Opus 4.7 is an enchancment on Opus 4.6; in others (resembling its tendency to offer overly detailed harm-reduction recommendation on managed substances), Opus 4.7 is modestly weaker. Our alignment evaluation concluded that the mannequin is “largely well-aligned and trustworthy, though not fully ideal in its behavior”. Note that Mythos Preview stays the best-aligned mannequin we’ve skilled in keeping with our evaluations. Our security evaluations are mentioned in full within the Claude Opus 4.7 System Card.
Also launching right this moment
In addition to Claude Opus 4.7 itself, we’re launching the next updates:
- More effort management: Opus 4.7 introduces a brand new
xhigh(“extra high”) effort level betweenexcessiveandmax, giving customers finer management over the tradeoff between reasoning and latency on arduous issues. In Claude Code, we’ve raised the default effort degree toxhighfor all plans. When testing Opus 4.7 for coding and agentic use circumstances, we suggest beginning withexcessiveorxhigheffort. - On the Claude Platform (API): in addition to help for higher-resolution photographs, we’re additionally launching job budgets in public beta, giving builders a option to information Claude’s token spend so it may possibly prioritize work throughout longer runs.
- In Claude Code: The new
/ultrareviewslash command produces a devoted assessment session that reads by modifications and flags bugs and design points {that a} cautious reviewer would catch. We’re giving Pro and Max Claude Code customers three free ultrareviews to strive it out. In addition, we’ve prolonged auto mode to Max customers. Auto mode is a brand new permissions choice the place Claude makes choices in your behalf, that means that you could run longer duties with fewer interruptions—and with much less threat than for those who had chosen to skip all permissions.
Migrating from Opus 4.6 to Opus 4.7
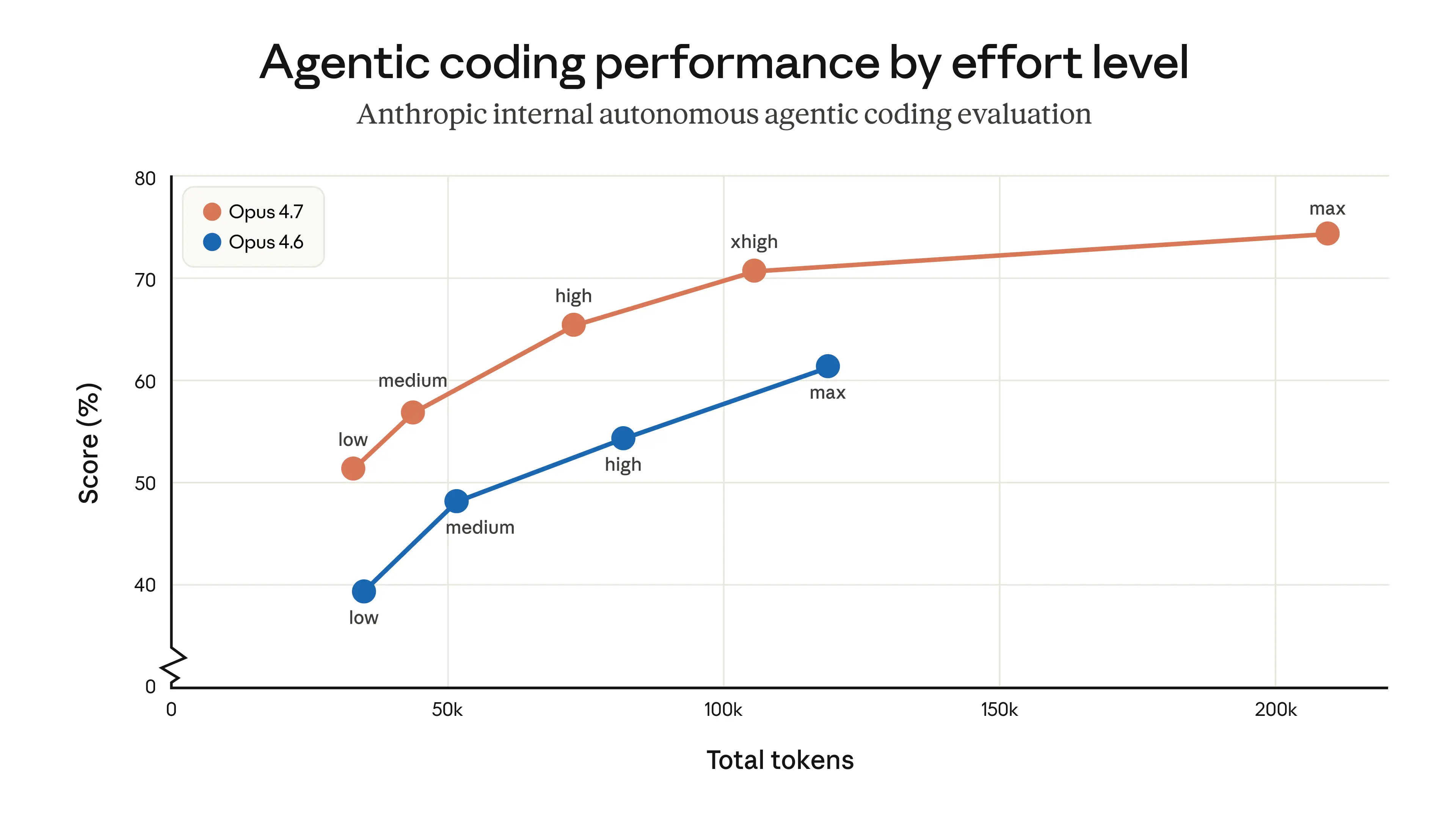
Opus 4.7 is a direct improve to Opus 4.6, however two modifications are value planning for as a result of they have an effect on token utilization. First, Opus 4.7 makes use of an up to date tokenizer that improves how the mannequin processes textual content. The tradeoff is that the identical enter can map to extra tokens—roughly 1.0–1.35× relying on the content material sort. Second, Opus 4.7 thinks extra at larger effort ranges, significantly on later turns in agentic settings. This improves its reliability on arduous issues, however it does imply it produces extra output tokens.
Users can management token utilization in numerous methods: by utilizing the trouble parameter, adjusting their job budgets, or prompting the mannequin to be extra concise. In our personal testing, the online impact is favorable—token utilization throughout all effort ranges is improved on an inside coding analysis, as proven under—however we suggest measuring the distinction on actual visitors. We’ve written a migration guide that gives additional recommendation on upgrading from Opus 4.6 to Opus 4.7.